注意: この記事では Stormworks のセーブデータや内部データを外部から読み取り、編集します。この記事に掲載したプログラムをご自身で実行する場合は、内容を十分理解してから始めてください。
動機と目標
ある程度複雑なビークルになると、電気配線をする必要のあるブロックが増えてきます。普通は電気ノードのあるブロックはすべてバッテリーかブレーカーに繋げておけばいいのですが、1つずつ手動で行わないといけません。電気ノードのあるブロックが多くなるとこの作業は大変ですし、手動で行う以上繋ぎ忘れなどミスもつきものです。そこで、この作業を自動化して楽をしつつミスを減らすことを目指します。
アプローチ
ビークルデータはXMLファイルなので、これを外部から編集することで電気配線を繋げたり消したりできるはずです。今回はPythonを使って、元となるビークルファイルを渡すと電気配線を済ませたビークルファイルを出力するようなプログラムを作っていきます。Pythonである必要は特にないので、XMLの読み書きができるならどの言語でやってもよいでしょう。
ビークルファイルの構造を調べる
試しに電気関連パーツをいくつかつけただけの小規模なビークルを作成し、XMLファイルを見てビークルのXMLの構造を調べてみました。(今回関係ないものは省いています)
<vehicle> (ビークル全体)
├── <bodies>
│ └── <body> (いわゆるマージ)
│ └── <components>
│ └── <c d="{パーツ種類}">
│ └── <o r="{パーツの回転を示す行列}">
│ └── <vp x="{X座標}" y="{Y座標}" z="{Z座標}"> (パーツ位置)
└── <logic_node_links>
└── <logic_node_link type="{電気配線は4}">
├── <voxel_pos_0 x="{X座標}" y="{Y座標}" z="{Z座標}">
└── <voxel_pos_1 x="{X座標}" y="{Y座標}" z="{Z座標}">
電気配線は、<logic_node_link type="4"> で表されているようです。その中の <voxel_pos_0> と <voxel_pos_1> で、どことどこを繋げるかを指定しています。未接続の電気ノードの座標がわかれば、新たな電気配線を追加することも可能そうです。
しかし、ビークルファイルだけでは未接続の電気ノードがどこにあるかわかりません。電気ノードのビークル内座標を調べるためには、各パーツの電気ノードの位置と、パーツそのものの座標と回転の情報が必要になります。パーツの種類、座標、回転は <c> とその中身を見ればよさそうですので、次にパーツの種類ごとの電気ノードを位置を調べます。
パーツ定義ファイルの構造を調べる
パーツの情報もXMLファイルで定義されています。Stormworksをインストールしたフォルダ (stormworks.exe のあるフォルダ) から、rom/data/definitions にパーツ定義のXMLファイルがあります。Stormworks をインストールしたフォルダは、Steam から 歯車アイコン→管理→ローカルファイルを閲覧 を押すと開くことができます。
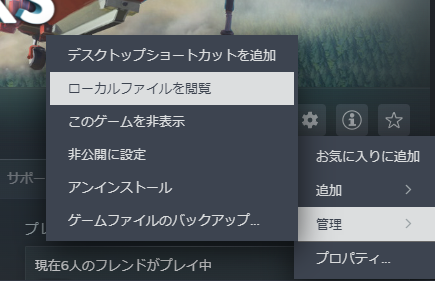
こちらも同様に、関係のあるものだけ抜粋すると次のような構造になっています。
<definition> (パーツ定義)
└── <logic_nodes>
└── <logic_node type="{電気配線は4}">
└── <position x="{X座標}" y="{Y座標}" z="{Z座標}">
パーツ定義に書かれている座標はパーツの基準位置からの相対座標のため、電気ノードのビークル内での絶対座標を得るためにはビークル内のパーツ位置とパーツの回転を考慮する必要があります。
ビークルファイルに書かれているパーツ名はパーツ定義ファイルの名前と一致しているようなので、まずはその名前と電気ノードの有無と電気ノードの位置の対応表を作ります。次に、ビークルファイルを見てビークル内の電気ノードの座標をリストアップし、電気ノード間を繋ぐ配線を追加し、最後に配線済みのビークルファイルを書き出します。
実装
ここから作業を始めていきます。適当な場所に新しいフォルダを作り、誤ってパーツ定義ファイルを変更してしまわないよう definitions フォルダをコピーして持ってきます。
パーツ-電気ノード位置 対照表
パーツ定義ファイルの名前と電気ノードの位置の対照表を作ります。今回は一旦JSON形式で保存することにします。作業フォルダ内で下記の Python を実行すれば electric_nodes.json というファイルが作成されます。
from collections import defaultdict import json import os import xml.etree.ElementTree as ET # パーツ定義ファイルのあるフォルダ DEFINITIONS_PATH = 'definitions' # パーツ名と電気ノード位置を記録 elec_nodes = defaultdict(lambda: []) for filename in os.listdir(DEFINITIONS_PATH): name, ext = os.path.splitext(filename) # .xml のファイル以外を無視 if ext != '.xml': continue with open(os.path.join(DEFINITIONS_PATH, filename), mode='r') as f: definition = f.read() # <logic_nodes> と </logic_nodes> で挟まれた部分を切り出す start_idx = definition.find('<logic_nodes>') end_idx = definition.find('</logic_nodes>') if start_idx != -1 and end_idx != -1: # XMLとして読み取り root = ET.fromstring(definition[start_idx:end_idx] + '</logic_nodes>') # type="4" のノードのみ抽出 for elec_node in root.findall('logic_node[@type="4"]'): position = elec_node.find('position').attrib # 電気ノード座標を記録 elec_nodes[name].append(( int(position.get('x', 0)), int(position.get('y', 0)), int(position.get('z', 0)) )) # JSON形式で書き出し with open('electric_nodes.json', mode='w') as f: json.dump(elec_nodes, f)
次のような内容になっています。
- definitions 内の拡張子が .xml のファイルをすべて見つける
- それぞれに対して、
<logic_nodes>と</logic_nodes>で挟まれた部分の文字列を切り出し、XMLとして読み取る <logic_node>タグで属性にtype="4"をもつものをすべて見つける- その中の
<position>タグのx、y、z属性を取得し、ファイル名と対応付けて記録する - 記録した電気ノード位置をJSONとして書き出す
ここで、ファイルを直接XMLとして読み取るのではなく文字列処理で <logic_nodes> だけを読み取っているのには理由があります。ファイル全体をXMLとして読み取ろうとすると、一部のファイルでエラーとなりうまくいきません。これは Stormworks のXMLファイルがXMLとしてのルールに違反している箇所があるからです。本来XMLの属性名は数字から始めることはできませんが、今回関係ない部分で数字から始まる属性名が存在します。Stormworks 本体のXMLパーサはある意味いい加減で、これをそのまま読み取ってしまいますが、Python の xml ライブラリはちゃんとしていて、ルール違反のXMLを読み取ろうとするとエラーを出してしまいます。これを回避するため、今回関係のある <logic_nodes> 内を無理やり文字列処理で切り出してからXMLとして読み取っています。
これで、electric_nodes.json としてパーツごとの電気ノード位置の対照表を得ることができました。大半のパーツは電気ノードを1つまでしか持ちませんが、Circuit Breaker、Charger、Relay の3つだけは電気ノードを2個持っていることがわかります。また、大半のパーツは電気ノードを (0, 0, 0) に持ちますが、中・大バッテリーなどの大きなパーツは基準位置が端にあるのに対して電気ノードはパーツ中心付近にあるため、電気ノード位置が (0, 0, 0) ではない位置にあります。
ビークルに電気配線を追加
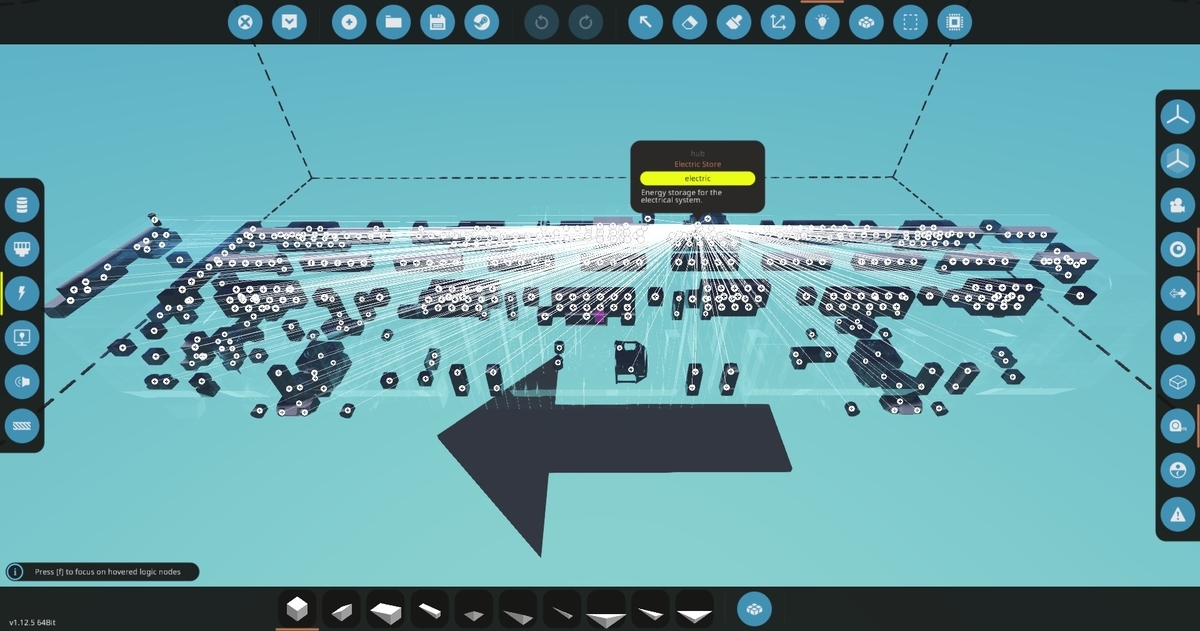
本記事のメインです。ビークルであらかじめバッテリーやブレーカーなど、名前のつけられるパーツに hub という名前をつけておくと、そこから全ての電気ノードに電気配線を済ませた新しいビークルファイルを output フォルダに出力します。既存の電気配線は一旦すべて削除する仕様になっています。
import argparse import json import os import re import xml.etree.ElementTree as ET import numpy as np # コマンド引数 parser = argparse.ArgumentParser() parser.add_argument('input', type=str) parser.add_argument('--hub-name', type=str, default='hub') parser.add_argument('-o', '--output', type=str, required=False) args = parser.parse_args() # ファイル出力先 output_path = args.output if output_path is None: output_path = 'output/' + os.path.basename(args.input) # 電気ノード位置 definitions = {} with open('electric_nodes.json') as f: definitions = json.load(f) # ファイルを読み取り tree= ET.parse(args.input) root= tree.getroot() logic_links = root.find('logic_node_links') # 放射状の配線の中心となるハブの電気ノード位置 hub_node = None # それ以外の電気ノード位置 electric_nodes = [] for body in root.findall('bodies/body'): for component in body.findall('components/c'): name = component.attrib.get('d', '01_block') # 電気ノードのないパーツは無視 if name not in definitions: continue # パーツの座標 o = component.find('o') vp = o.find('vp') if vp is None: continue pos = np.array((vp.attrib.get('x', 0), vp.attrib.get('y', 0), vp.attrib.get('z', 0)), dtype=int) r = np.identity(3) if 'r' in o.attrib: # パーツの回転情報 r = np.array(o.attrib['r'].split(','), dtype=int).reshape((3, 3)) custom_name = o.get('custom_name') for node_def in definitions[name]: # 電気ノードの絶対位置を計算 node_pos = pos + np.array(node_def, dtype=int) @ r # 電気ノード位置を記録 if custom_name == args.hub_name: hub_node = node_pos else: electric_nodes.append(node_pos) # 一旦電気配線をすべて削除 for link in logic_links.findall('logic_node_link[@type="4"]'): logic_links.remove(link) # ハブが存在しなければエラー if hub_node is None: raise ValueError(f'No electric block with custom name "{args.hub_name}".') # [X, Y, Z] の形から {x: X, y: Y, z: Z} の形に変換 def pos_attrib(pos): attrib = {} for i, n in enumerate('xyz'): if pos[i] != 0: attrib[n] = str(pos[i]) return attrib # 各ノードとハブを繋げる配線を追加 for node in electric_nodes: link = ET.Element('logic_node_link', attrib={'type': '4'}) pos0 = ET.Element('voxel_pos_0', attrib=pos_attrib(hub_node)) pos1 = ET.Element('voxel_pos_1', attrib=pos_attrib(node)) link.append(pos0) link.append(pos1) logic_links.append(link) # <logic_node_links> の新しい文字列表現 logic_links_str = ET.tostring(logic_links).decode() # ビークルファイルを文字列として読み取り vehicle_file_str = None with open(args.input, mode='r') as f: vehicle_file_str = f.read() # ビークルファイルの <logic_node_links> を新しいものに置換 vehicle_file_str = re.sub(r'(<logic_node_links>.*</logic_node_links>|<logic_node_links/>)', logic_links_str, vehicle_file_str, flags=re.MULTILINE | re.DOTALL) # 新しいビークルファイルを書き出し os.makedirs(os.path.dirname(output_path), exist_ok=True) with open(output_path, mode='w', newline='\n') as f: f.write(vehicle_file_str)
もとのビークルファイルをなるべく保持するため、書き出すときは文字列処理で <logic_node_links> だけを置き換えるようになっています。既存の電気配線を削除せず、すでに配線済みのノードには配線しないようにするようにするなど、お好みに応じて変更してもよいでしょう。
まとめ
ビークルに限らず、Stormworks のセーブデータにはXMLがよく使われるので、単調で面倒な作業があれば自動化することができます。その際、残念ながら Stormworks のXMLは構文規則に違反している箇所があるため、しっかり作られているXMLパーサではエラーになってしまうことがあることに注意しましょう。エラーを回避するために強引ですがあらかじめ文字列処理を行う必要があるかもしれません。こうしたやり方はプログラムのバグを招きやすいので十分注意する必要がありますが、それでも面倒な作業を自動化することができるとより Stormworks が捗るでしょう。